InnoDB Page Merging and Page Splitting
원문 : InnoDB Page Merging and Page Splitting (April 10, 2017)
MySQL InnoDB 에서는 primary key 의 설계가 중요합니다. InnoDB 의 경우에는 index merges 과 page splits 에 대해서 알아야할 필요가 있습니다. 이 두 가지 개념은 성능과 밀접하게 관련되어 있으므로 (PK뿐만 아니라) 모든 인덱스를 설계할 때 이 관계를 고려해야 합니다. InnoDB 에서는 모든 데이터가 Index 입니다.
File-Table Components
windmills schema 에 wmills 라는 table 이 있다고 가정해 보겠습니다. data directory (/var/lib/mysql/)에는 다음이 포함되어 있는 것을 확인할 수 있습니다.
1
2
3
4
data/
windmills/
wmills.ibd
wmills.frm
이는 innodb_file_per_table 설정이 1(활성화)로 설정되어 있기 때문입니다. 해당 설정을 사용하면 schema 의 각 table 이 하나의 파일로 표시됩니다. (table 이 partition 되어 있는 경우 여러개의 파일이 될 수 있음)
여기서 중요한 것은 물리적 컨테이너가 wmills.ibd 라는 파일이라는 것입니다. 이 파일은 여러개의 segments 로 나누어져 있습니다. 각 segments 는 Index 와 연결됩니다.
파일의 크기는 row 를 삭제해도 줄어들지 않지만, segments 자체는 extent 라는 하위 요소와의 관계에서 커지거나 줄어들 수 있습니다. extent 는 segments 내에만 존재할 수 있으며, 1MB 의 고정 크기를 갖습니다. page 는 extent 의 하위 요소이며 기본 크기는 16KB 입니다.
따라서 extent 는 최대 64page 를 포함할 수 있습니다. page 에는 2~N개의 row 가 포함될 수 있습니다. page 에 포함될 수 있는 row 수는 table schema 에 정의된 row 크기와 관련이 있습니다. InnoDB 에는 최소한 두개의 row 가 이 하나의 page 에 들어가야 한다는 규칙이 있습니다. 따라서 row 하나의 최대 크기는 8000byte 로 제한되어 있습니다.
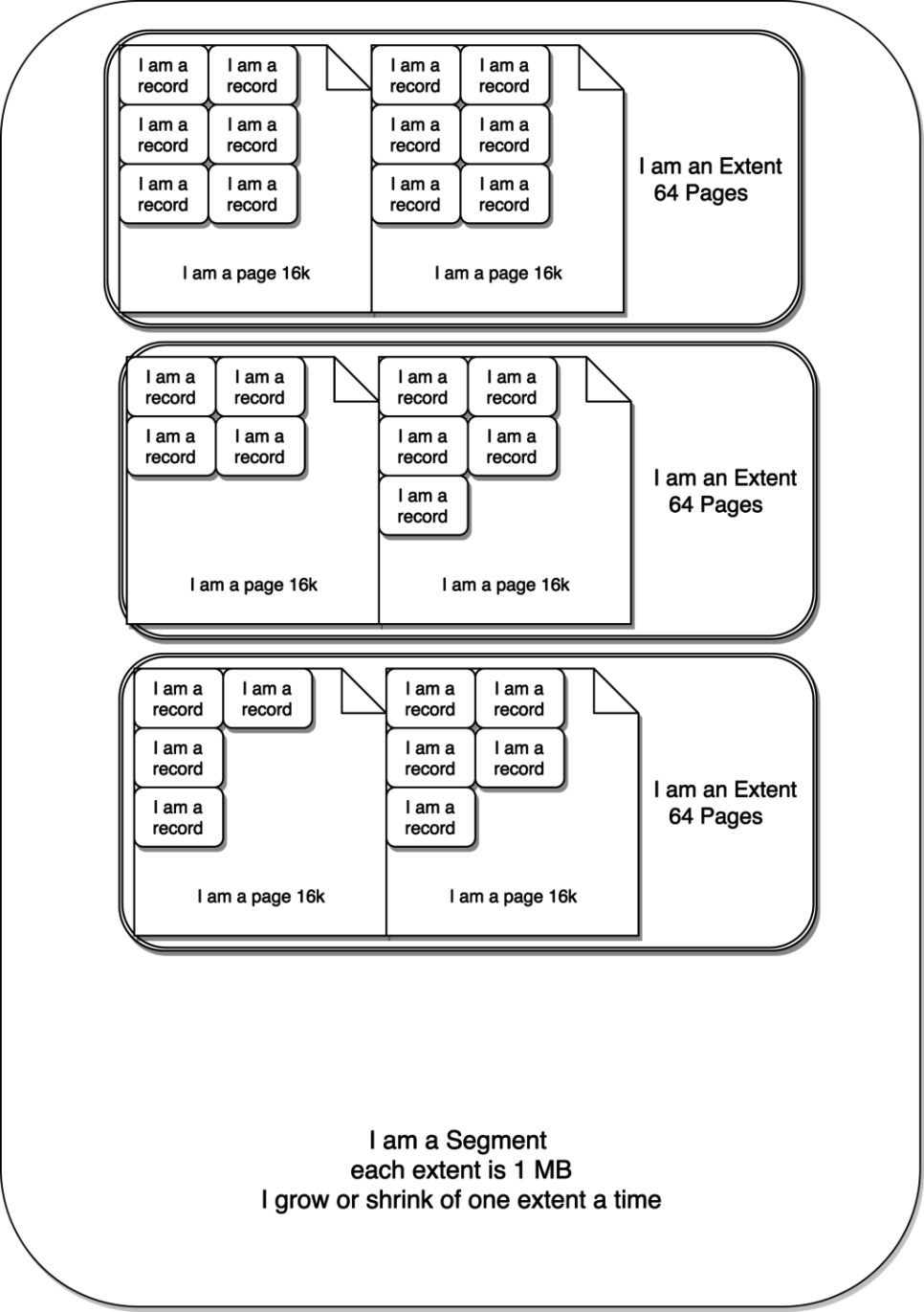
InnoDB 는 B-tree 를 사용하여 segments 내에서 extents 에 걸쳐 page 내부의 데이터를 구성합니다.
Roots, Branches, and Leaves
각 page(leap)에는 primary key 로 구성된 2-N개의 row 가 포함되어 있습니다. tree 에는 다양한 branch 를 관리하기 위한 special pages 가 있습니다. 이를 internal nodes(INode) 라고 합니다.
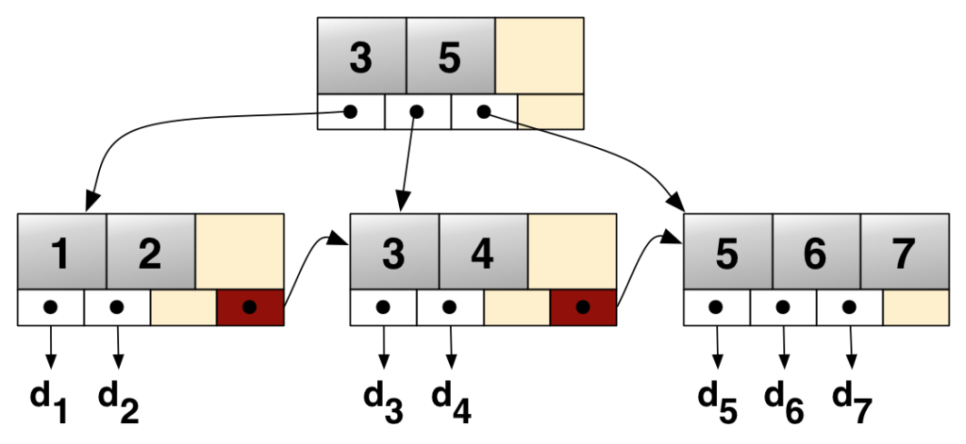
이 이미지는 단지 예시일 뿐이며 아래 코드의 실제 출력을 나타내지는 않습니다. 세부 사항을 살펴보겠습니다.
1
2
3
4
5
6
ROOT NODE #3: 4 records, 68 bytes
NODE POINTER RECORD ≥ (id=2) → #197
INTERNAL NODE #197: 464 records, 7888 bytes
NODE POINTER RECORD ≥ (id=2) → #5
LEAF NODE #5: 57 records, 7524 bytes
RECORD: (id=2) → (uuid="884e471c-0e82-11e7-8bf6-08002734ed50", millid=139, kwatts_s=1956, date="2017-05-01", location="For beauty's pattern to succeeding men.Yet do thy", active=1, time="2017-03-21 22:05:45", strrecordtype="Wit")
아래는 table 구조입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
CREATE TABLE `wmills` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`uuid` char(36) COLLATE utf8_bin NOT NULL,
`millid` smallint(6) NOT NULL,
`kwatts_s` int(11) NOT NULL,
`date` date NOT NULL,
`location` varchar(50) COLLATE utf8_bin DEFAULT NULL,
`active` tinyint(2) NOT NULL DEFAULT '1',
`time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`strrecordtype` char(3) COLLATE utf8_bin NOT NULL,
PRIMARY KEY (`id`),
KEY `IDX_millid` (`millid`)
) ENGINE=InnoDB;
B-tree 의 모든 스타일에는 root node 라는 진입점이 있습니다. 여기서는 3page 로 확인되었습니다. root page 에는 Index ID, Inode 수 등과 같은 정보가 포함되어 있습니다. INode page 에는 page 자체에 대한 정보, 값 범위 등이 포함되어 있습니다. 마지막으로 데이터를 찾을 수 있는 leaf nodes 가 있습니다. 이 예에서는 leaf nodes #5에 총 7524byte 에 대해 57개의 record 가 있음을 확인할 수 있습니다. 해당 줄 아래에는 rocord 가 있으며 row 데이터를 볼 수 있습니다.
여기서의 개념은 데이터를 table 과 row 로 구성하는 동안 InnoDB 는 데이터를 branches, pages, records 로 구성한다는 것입니다. InnoDB 는 단일 row 기반으로 작동하지 않는다는 점을 명심하는 것이 매우 중요합니다. InnoDB 는 항상 page 에서 작동합니다. page 가 로드되면 해당 page 에서 요청한 row/records 를 검색합니다.
Page Internals
page 는 비어 있거나 완전히 채워질 수 있습니다(100%). row-records 는 PK 별로 구성됩니다. 예를 들어 테이블이 AUTO_INCREMENT 를 사용하고 있다면, sequence ID=1, 2, 3, 4 순이 됩니다.
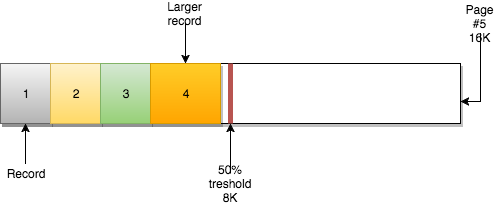
page 에는 또 다른 중요한 속성인 MERGE_THRESHOLD도 있습니다. 이 매개변수의 기본값은 page 의 50% 이며 InnoDB merge activity 에서 매우 중요한 역할을 합니다.
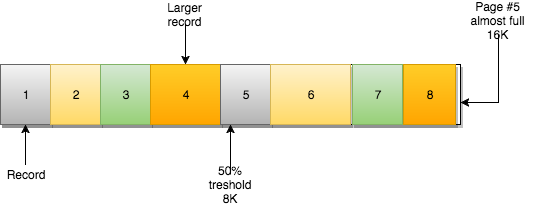
데이터를 삽입하는 동안 records 를 page 내부에 저장할 수 있다면 page 가 순차적으로 채워집니다. page 가 가득 차면 다음 레코드가 NEXT 페이지에 저장됩니다.
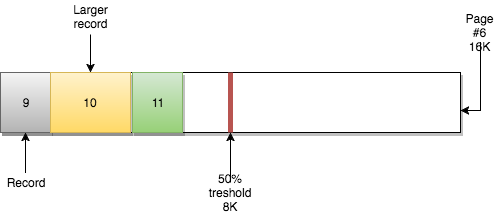
B-tree 의 특성상 이 구조는 branches 를 따라 하향식으로 수직 탐색을 할 수 있을 뿐만 아니라 leaf nodes 를 가로질러 수평 탐색을 할 수도 있습니다. 이는 다음 record 값이 저장되어 있는 page 를 가리키는 포인터를 leaf nodes page 가 가지고 있기 때문입니다.
예를 들어, page #5 에는 다음 page 의 page #6 에 대한 참조를 가지고 있습니다. page #6 에는 이전 page(page #5)에 대한 참조와 다음 page(page #7)에 대한 참조를 가지고 있습니다.
linked list 의 이러한 메커니즘을 사용하면 빠른 순차 스캔(i.e., Range Scans)이 가능합니다. 앞서 언급했듯이 이는 AUTO_INCREMENT를 기반으로 PK 를 삽입하고 가질 때 발생합니다. 하지만 값을 삭제하기 시작하면 어떻게 되나요?
Page Merging
record 를 삭제해도 해당 record 는 물리적으로 삭제되지 않습니다. 대신 record 에 삭제된 flag 를 지정하고 사용된 공간을 회수할 수 있게 됩니다.
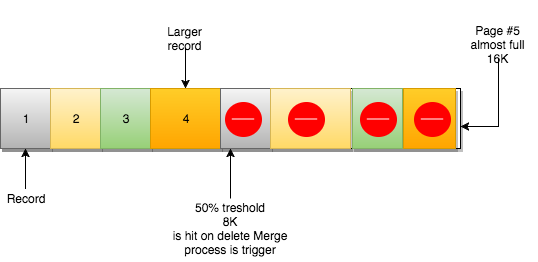
page 가 MERGE_THRESHOLD(page 크기의 50%)와 일치할 만큼 삭제되면 InnoDB 는 가장 가까운 page(NEXT 및 PERIVE)를 찾아 두개의 page 를 병합하여 공간 활용률을 최적화할 수 있는지 확인하기 시작합니다.
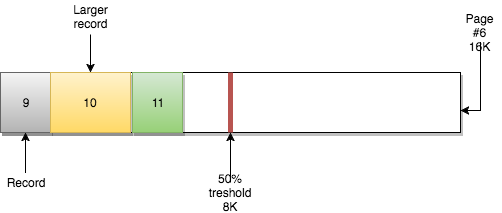
위의 예에서 page #6 은 공간의 절반 미만을 활용하고 있습니다. page #5 는 많은 삭제를 받았으며 현재도 50% 미만으로 사용되었습니다. InnoDB 의 관점에서 보면 다음과 같이 병합이 가능합니다.
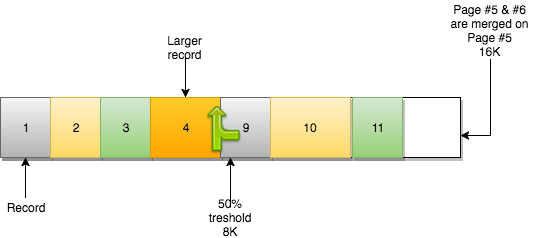
병합 작업으로 인해 이전 데이터와 page #6 의 데이터가 포함된 page #5 이 생성됩니다. page #6 은 새로운 데이터를 저장할수 있는 비어있는 page 가 됩니다.
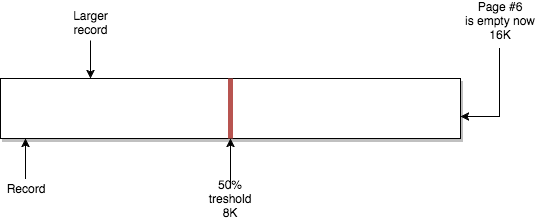
record 를 업데이트하고 새로운 record 의 크기로 인해 page 가 임계값 아래로 내려갈 때도 동일한 프로세스가 발생합니다.
규칙은 다음과 같습니다. 병합작업은 인접한 linked pages 와 관련된 delete 및 update 작업에서 발생합니다. 병합작업이 성공하면 INFORMATION_SCHEMA.INNODB_METRICS 의 index_page_merge_successful 지표가 증가합니다.
Page Splits
위에서 언급했듯이 한 page 를 100%까지 채울 수 있습니다. 이 경우 다음 page 에 새 레코드가 들어갑니다.
하지만 다음과 같은 상황이 발생하면 어떻게 될까요?
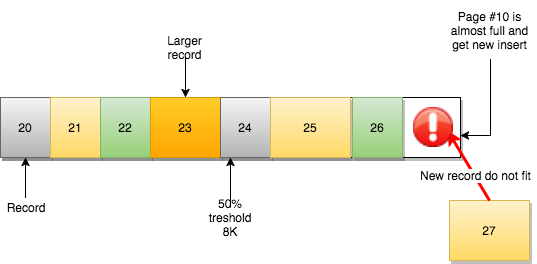
page #10 에는 새로운(또는 업데이트된) record 를 저장할 공간이 부족합니다. 다음 page 논리에 따라 record 는 page #11 로 이동해야 합니다. 그러나,
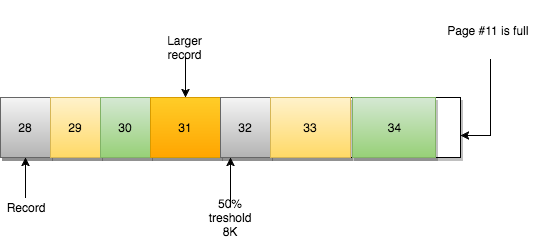
page #11 도 가득 차서 데이터를 순서대로 삽입할 수 없습니다. 그렇다면 무엇을 할 수 있습니까?
우리가 이야기한 linked list 를 기억하시나요? 현재 page #10 에는 Prev=9 및 Next=11 이 있습니다.
InnoDB 가 수행할 작업은 다음과 같습니다.
- 새로운 page 만들기
- 원본 page(page #10)를 분할할 수 있는 위치 식별 (record 수준에서)
- record 이동
- page 관계 재정의
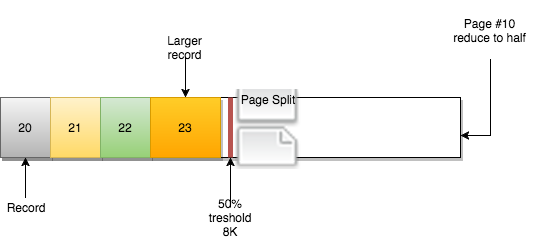
새로운 page #12 가 생성됩니다.
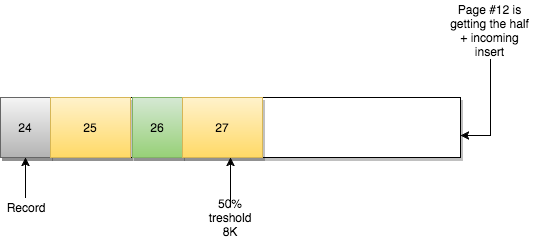
page #11 는 그대로 유지됩니다. 변경되는 것은 page 간의 관계입니다.
- page #10 에는 Prev=9 및 Next=12 가 있습니다.
- page #12 Prev=10 및 Next=11
- page #11 Prev=12 및 Next=13
B-tree 의 경로는 논리적 조직을 따르기 때문에 여전히 일관성을 보입니다. 그러나 물리적으로는 page 가 순서대로 배치되지 않고 대부분의 경우 다른 위치에 있습니다.
일반적으로 다음과 같이 말할 수 있습니다. Page splits 은 insert 또는 update 할때 발생하며 page dislocation 가 발생합니다 (대부분의 경우 다른 extents 에서)
InnoDB 는 INFORMATION_SCHEMA.INNODB_METRICS 에서 page splits 를 추적합니다. index_page_splits 및 index_page_reorg_attempts/successful 지표를 찾아보세요.
split page 가 생성되면 뒤로 이동하는 유일한 방법은 생성된 page 를 merge threshold(병합 임계값) 아래로 낮추는 것입니다. 그런 일이 발생하면 InnoDB 는 병합 작업을 통해 split page 에서 데이터를 이동합니다.
다른 방법은 table 을 OPTIMIZE 하여 데이터를 재구성하는 것입니다. 이는 매우 무겁고 긴 프로세스일 수 있지만, 너무 많은 page 가 산발적으로 extents 에 위치한 상황에서 회복하는 유일한 방법입니다.
또 다른 점은 merges 및 splits 작업 중 InnoDB 가 index tree 에 대해 x-latch를 획득한다는 것입니다. 시스템이 바쁠 때 이것은 문제가 될 수 있습니다. 이로 인해 index latch 경합이 발생할 수 있습니다. Merges 및 splits(즉, 쓰기)이 단일 page 에만 영향을 미치지 않는 경우, 이는 InnoDB 에서 ‘optimistic’ 업데이트라고 하며, 이 경우 latch 는 S 모드로만 획득됩니다. Merges 및 splits 은 ‘pessimistic’ 업데이트라고 하며, latch 는 X 모드로 획득됩니다.
My Primary Key
좋은 Primary Key(PK)는 데이터를 검색하는 데 중요할 뿐만 아니라 쓰는 동안 extents 내에서 데이터를 올바르게 분배하는 데 중요합니다. (이는 merges 및 splits 작업의 경우에도 관련됨)
첫 번째 경우에는 단순한 auto-increment 를 사용합니다. 두 번째 경우에는 PK 를 ID(1-200 range)와 auto-increment 값으로 사용합니다. 세 번째 경우에는 동일한 ID(1-200 범위)를 가지고 있지만 UUID 와 연관됩니다.
Insert 할 때, InnoDB 는 page 를 추가해야 합니다. 이것은 SPLIT 연산으로 읽혀집니다.
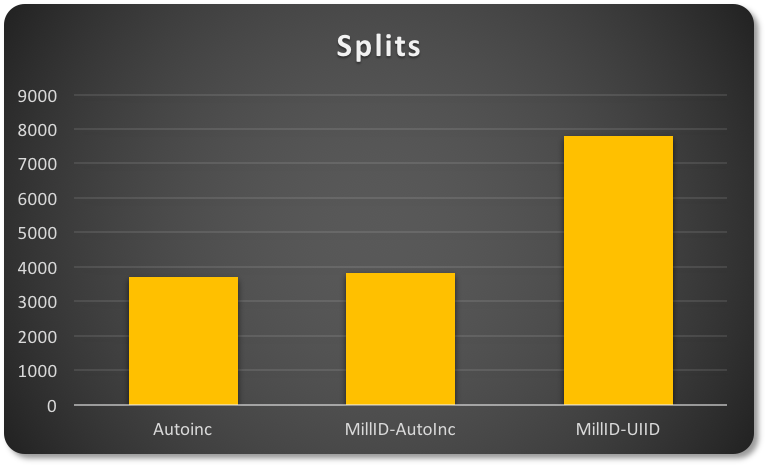
첫번째, 두번째, 세번째 사용하는 Primary Key 의 종류에 따라 동작이 상당히 다릅니다.
첫 번째와 두 번째 경우에는 ‘compact’ 데이터 분포를 가집니다. 이는 공간 활용도가 더 높음을 의미하며, 반면에 UUID 의 semi-random 특성은 상당한 ‘sparse’ page 분포를 초래합니다. (더 많은 페이지와 관련된 분할 작업을 유발함)
page merge 의 경우에는 PK 유형에 따라 merge 시도 횟수는 더욱 차이가 납니다.
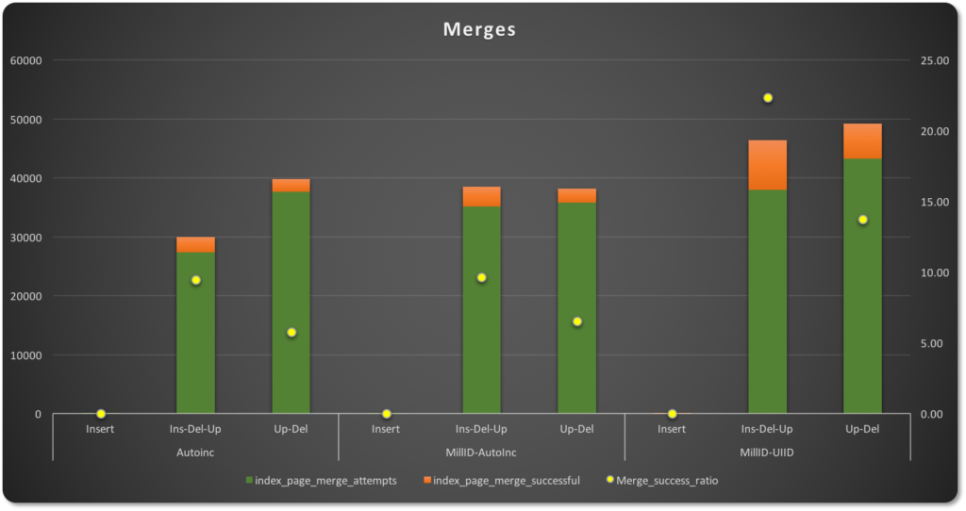
Insert-Update-Delete 작업에서 auto-increment 값은 다른 두 유형보다 page merge 시도가 적고 성공 비율도 9.45% 낮습니다. 반면, UUID를 사용하는 PK 는 merge 시도가 더 많지만, ‘sparse’ 분포로 인해 많은 page 가 부분적으로 비어 있어 성공 비율이 22.34%로 상당히 높습니다.
유사한 숫자를 가진 PK 값도 econdary index 에서 나옵니다.
Conclusion
MySQL InnoDB 는 이러한 작업들을 지속적으로 수행하지만, 사용자는 이를 잘 볼 수 없습니다. 안타깝게도 서버 측에서 매개변수나 다른 방법을 사용하여 이를 최적화할 수 있는 방법은 거의 없습니다. 하지만 좋은 소식은 설계 시점에 많은 것을 할 수 있다는 것입니다.
적절한 primary Key 를 사용하고 secondary index 를 설계하되, 이를 남용하지 않도록 주의해야 합니다. inserts/deletes/updates 가 매우 많을 것으로 예상되는 테이블에 적절한 유지 관리 기간을 계획하세요.
이것은 중요한 점입니다. InnoDB 에서는 단편화된 record 를 가질 수 없지만 page-extent 수준에서는 악몽이 될 수 있습니다. table 유지 관리를 무시하면 I/O, memory 및 InnoDB buffer pool 에서 더 많은 작업이 발생합니다.
일정한 간격으로 일부 table 을 재구성해야 합니다. partitioning 및 외부 도구(pt-osc)를 포함하여 필요한 모든 방법을 사용하십시오. 테이블이 거대해지고 완전히 조각화되는 것을 허용하지 마세요.
디스크 공간을 낭비하고 있습니까? 필요한 record 세트를 검색하기 위해 한개 page 가 아닌 세개 page 를 로드해야 합니까? 검색할 때마다 훨씬 더 많은 읽기가 발생하나요? 그것은 여러분의 잘못입니다.
부주의에 대한 변명의 여지가 없습니다!